
近日,机器学习三大国际顶级会议之一:The 12th International Conference on Learning Representations(ICLR 2024)公布了录用结果。上海交通大学计算机科学与工程系吕宝粮团队与上海零唯一思科技有限公司联合发表了题为“Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI”的论文。
目前基于脑电(EEG)信号的深度学习模型通常是为特定数据集和脑机接口(BCI)应用而设计的,这限制了模型的规模,从而削弱了脑电信号的表征能力和普适性。最近,大型语言模型(LLM)在文本处理方面取得了前所未有的成功,这些颠覆性的研究成果促使我们开展了大型脑电模型(LEM)的探索。我们希望大型脑电模型能突破不同任务类型脑电数据集的限制,通过无监督预训练获得脑电信号的通用表征能力,然后在不同的下游任务上对模型进行微调。
然而,与文本数据相比,通常脑电数据集的规模非常小,格式也千差万别。开发大型脑电模型面临着下列几方面的挑战:
1) 缺乏足够的脑电数据。
与自然语言和图像数据相比,收集大规模的脑电数据异常困难。此外,脑电数据的标注通常需要领域专家投入大量精力,从而导致只有少量标注的数据集可用于 BCI 中的特定任务,而这些任务的脑电信号通常是从少数被试收集到的,持续时间通常少于数十小时。因此,目前还没有一个足够大的脑电数据集来支持LEM的训练。
2) EEG信号采集的多样化配置。
尽管有国际通用的10-20系统来确保脑电信号采集的标准化,但用户仍可根据实际应用需要,选择使用不同电极编号或贴片电极的脑电帽来采集脑电数据。因此,如何处理不同格式的脑电数据,以匹配神经Transformer的输入单元,仍是一个需要探索的问题。
3) 缺乏有效的脑电表征学习范式。
脑电数据的低信噪比(SNR)和不同类型的噪声是一个非常棘手的问题。此外,平衡时间和空间特征对于有效的脑电表征学习至关重要。尽管有各种基于深度学习的脑电表征学习范式(如 CNN、RNN 和 GNN)可用于原始脑电数据处理,但由于上述问题,许多研究人员仍倾向于设计人工脑电特征。
本文的目标是设计一种通用的大型脑电模型,称为LaBraM。该模型可有效处理不同通道和长度的各种脑电数据。通过对大量脑电数据进行无监督训练,我们设想该模型将具备通用的脑电表征能力,使其能够快速适应各种脑电下游任务。为了训练LaBraM,我们从20个公开的脑电数据集中收集了超过2500个小时的各种任务和格式的脑电数据。
首先,我们将原始脑电信号分割成脑电信号通道片段,以解决不同电极和时间长度的问题。我们采用向量量化神经频谱预测训练语义丰富的神经标记器,以生成神经词汇。具体来说,标记器是通过预测原始信号的傅立叶频谱来训练的。在预训练期间,部分脑电片段会被掩蔽,而神经Transformer的目标是从可见片段中预测被掩蔽的标记。我们预训练了三个不同参数大小的模型,580万、4600万和3.69 亿,这是迄今为止 BCI 领域最大的模型。随后,我们在四种不同类型的下游任务上对它们进行了微调,这些任务包括分类和回归。

图1 LaBraM的整体架构。首先,所有输入的脑电信号将通过一个固定长度的时间窗口分割成脑电信号片段,然后对每个片段应用时间编码器提取时间特征。然后,将时间和空间嵌入添加到片段特征中,以携带时间和空间信息。最后,将嵌入序列按片段顺序传入Transformer编码器,以获得最终输出。
我们引入了神经Transformer,这是一种用于解码脑电信号的通用架构,可以处理任意通道数和时间长度的任何输入脑电信号,如图1所示。实现这一目标的关键操作是将脑电信号分割成块,其灵感来自图像中的片段嵌入。由于脑电在时间域的分辨率很高,因此在通过自我注意进行片段交互之前提取时间特征至关重要。我们采用由多个时域卷积块组成的时域编码器,将每个脑电片段编码成片段嵌入。时态卷积块由一维卷积层、组归一化层和GELU 激活函数组成。为了使模型能够感知片段嵌入的时间和空间信息,我们初始化了一个时间嵌入列表和一个空间嵌入列表。对于任意片段,我们将其对应的时间嵌入和空间嵌入加到片段嵌入上。最后,嵌入序列将直接输入Transformer编码器。
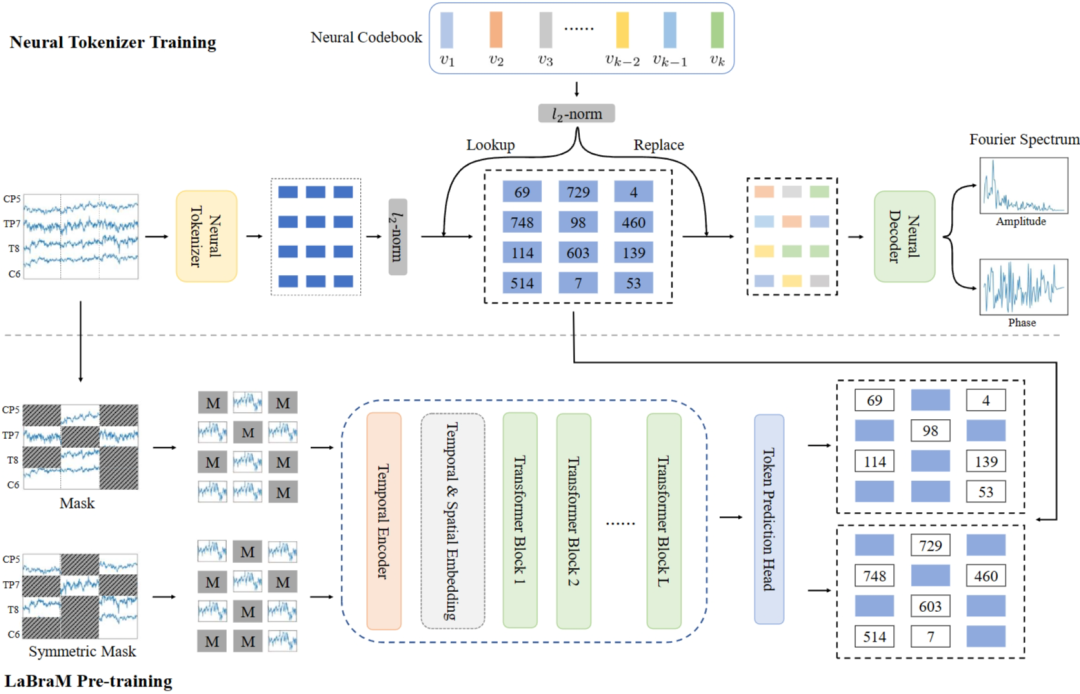
图2 神经标记符号训练和LaBraM预训练概述。上部分:我们训练神经标记器,通过重建傅立叶频谱将脑电信号离散为离散的神经标记。下部分:在预训练过程中,部分脑电片段会被掩蔽,而目标则是从可见片段中预测被掩蔽的标记。
在通过掩码和预测对LaBraM进行预训练之前,我们需要将脑电标记转化为离散的标记。我们提出了矢量量化神经频谱预测,它是通过预测傅立叶频谱来训练的,如图2上部分所示。其关键部分是将脑电样本编码成片段表示的神经标记器和从神经嵌入解码傅立叶频谱的神经解码器。为了让LaBraM利用大量脑电数据学习通用表征,我们提出了掩码脑电建模。整个过程如图二下部分所示。给定一个脑电样本,时序编码器首先将其转换为片段嵌入。我们随机生成一个掩码,被掩蔽的EEG片段将被加入时间和空间嵌入,然后输入变换器编码器,来预测掩蔽的EEG片段。我们进一步提出了一种对称掩码策略,以提高训练效率。
我们主要在两个下游任务数据集上验证LaBraM:TUAB和TUEV。我们设计了三种不同的LaBraM配置:LaBraM-Base、LaBraM-Large和LaBraM-Huge。LaBraM-Base的参数数为5.8M,LaBraM-Large为46M,LaBraM-Huge为369M。
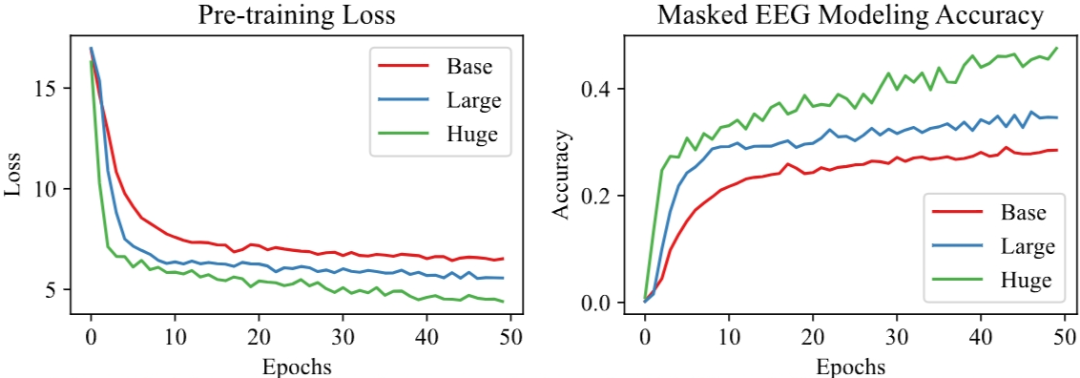
图3 预训练损失曲线和掩码脑电建模准确率曲线。
图3比较了Base模型、Large模型和Huge模型的预训练总损失和掩码脑电建模精度的收敛曲线。从图3可以看到,具有更多参数的大型模型可以收敛到更小的损失和更高的精度。值得注意的是,Huge模型的损失似乎有明显的下降趋势,而如果我们对其进行更长时间的训练,准确率则会趋于提高。这一观察结果表明,扩大模型规模有可能获得更好的性能。
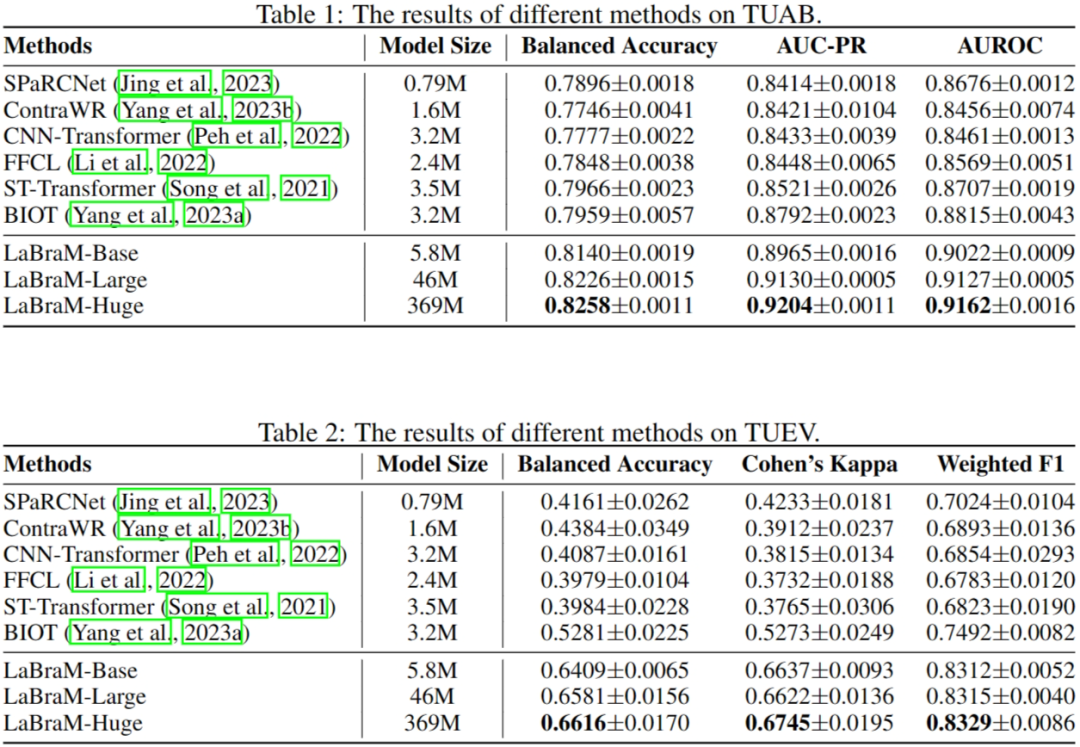
表1和表2列出了 TUAB 和 TUEV 中最佳的基线结果以及LaBraM的结果。很明显,我们的LaBraM-Base模型在这两项任务的各种评估指标上都优于所有基线模型。特别是在更具挑战性的 TUEV 多类分类任务中,我们的模型取得了显著的性能提升。在我们自己的模型中,我们观察到随着模型参数数量的增加,LaBraM-Huge模型的表现最好,其次是 LaBraM-Large模型,最后是LaBraM-Base模型。我们将这一良好表现归功于预训练数据量和模型参数的增加。我们推断,只要有足够多的脑电数据,大规模脑电模型就能学习到更通用的脑电表征,从而提高脑电信号在各种下游任务上的性能。

图4 比较模型在TUAB和TUEV数据集上的性能,是否将自身纳入预训练过程。
在预训练过程中,我们希望模型能够学习到不针对任何特定任务的通用脑电表征。虽然在预训练过程中没有使用标签数据,但为了消除预训练数据对下游任务的影响,我们比较了是否将下游任务数据集纳入预训练过程的结果。值得注意的是,TUAB和TUEV的记录与预训练数据集的记录是不相交的。如图4所示,是否将下游任务数据集纳入模型的预训练过程,对模型在下游任务上的性能影响不大。这表明我们的模型具有学习通用脑电表征的能力,并为将来收集更多脑电数据提供了指导。换句话说,我们不需要在预训练过程中花费大量精力标注脑电数据。
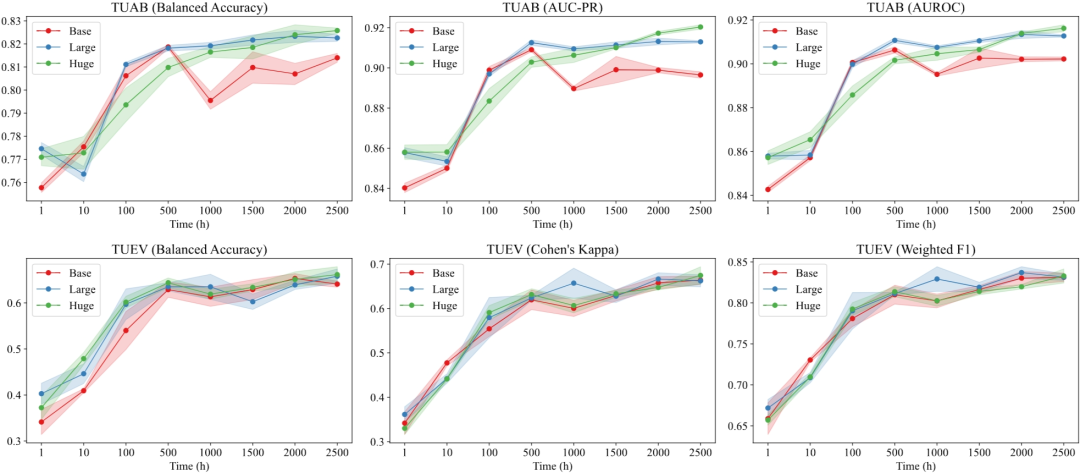
图5 随着预训练数据的增加,Base模型、Large模型和Huge模型在 TUAB 和 TUEV 数据集上的性能比较。
虽然我们已经收集了约2,500小时的脑电数据,但与自然语言处理和图像处理的样本量相比,仍然相对较小。我们通过调整预训练数据的大小来回答训练不同大小的 LaBraMs对数据大小的需求。如图5所示,训练时间为 500 小时的基本模型的性能超过了训练时间为2500小时的模型在TUAB上的性能,同时接近训练时间为 2500 小时的模型在 TUEV 上性能的 90%以上。对于Large模型来说,性能一般会随着数据量的增加而提高,尽管在 1000 小时后增速会放缓。相比之下,随着数据量的不断扩大,Huge模型的性能呈现出明显的上升趋势。因此,我们相信随着数据集的进一步扩大,我们的模型可以获得更好的性能。预训练大型脑电模型需要多少脑电数据,无疑是该领域值得探讨的重要问题。然而,2500 小时至少不是这个问题的答案。我们的观察结果基本上遵循了缩放定律(scaling law),由此我们推断,当数据量达到至少一万小时的数量级时,Huge模型将继续保持较好的性能。
上海交通大学计算机科学与工程系博士研究生姜卫邦为本文的第一作者,上海零唯一思科技有限公司赵黎明博士和上海交通大学计算机科学与工程系吕宝粮教授为本文共同通讯作者。
文章地址:https://openreview.net/forum?id=QzTpTRVtrP

零唯一思成立于2021年,使命是致力于情感智能技术的创新与实践,让机器更温馨地服务于人类。公司的愿景是为人们健康的情感世界,提供优质服务与支持。近期,为抑郁症患者提供基于多模态情感脑机接口技术的抑郁状态客观评估系统与数字疗法。未来,让机器能知人心、懂人意,打造适合于各类人群的智慧系统与情感服务机器人,共创温馨的和谐社会。

温馨智能|情感世界
